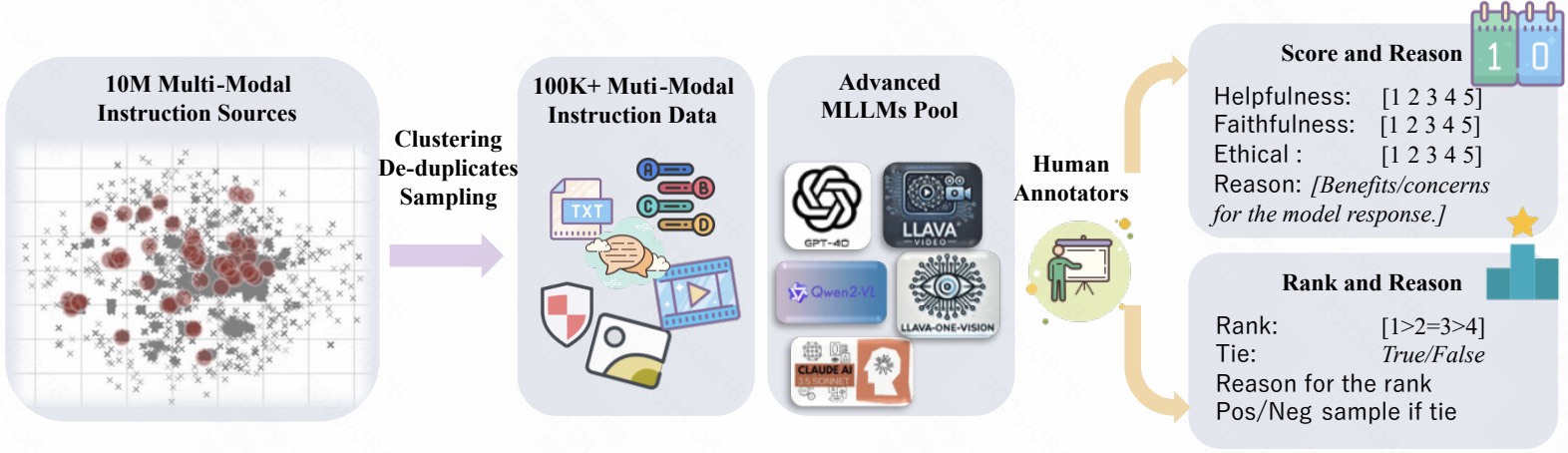
Despite notable advancements in Multimodal Large Language Models (MLLMs), most state-of-the-art models lack thorough alignment with human preferences, as current alignment research focuses on narrow areas (e.g., hallucination reduction) without exploring whether systematic preference alignment enhances overall capability. To address this, we introduce MM-RLHF—a dataset of 120k fine-grained, human-annotated preference comparison pairs surpassing existing resources in size, diversity, annotation granularity, and quality. Leveraging this, we propose key innovations: 1) a Critique-Based Reward Model that generates interpretable critiques before scoring outputs, providing more informative feedback than scalar rewards; and 2) Dynamic Reward Scaling, which optimizes training by adjusting sample loss weights according to reward signals. Rigorously evaluated across 10 dimensions and 27 benchmarks, our approach demonstrates consistent improvements—fine-tuning LLaVA-ov-7B yields 19.5% higher conversational ability and 60% better safety.
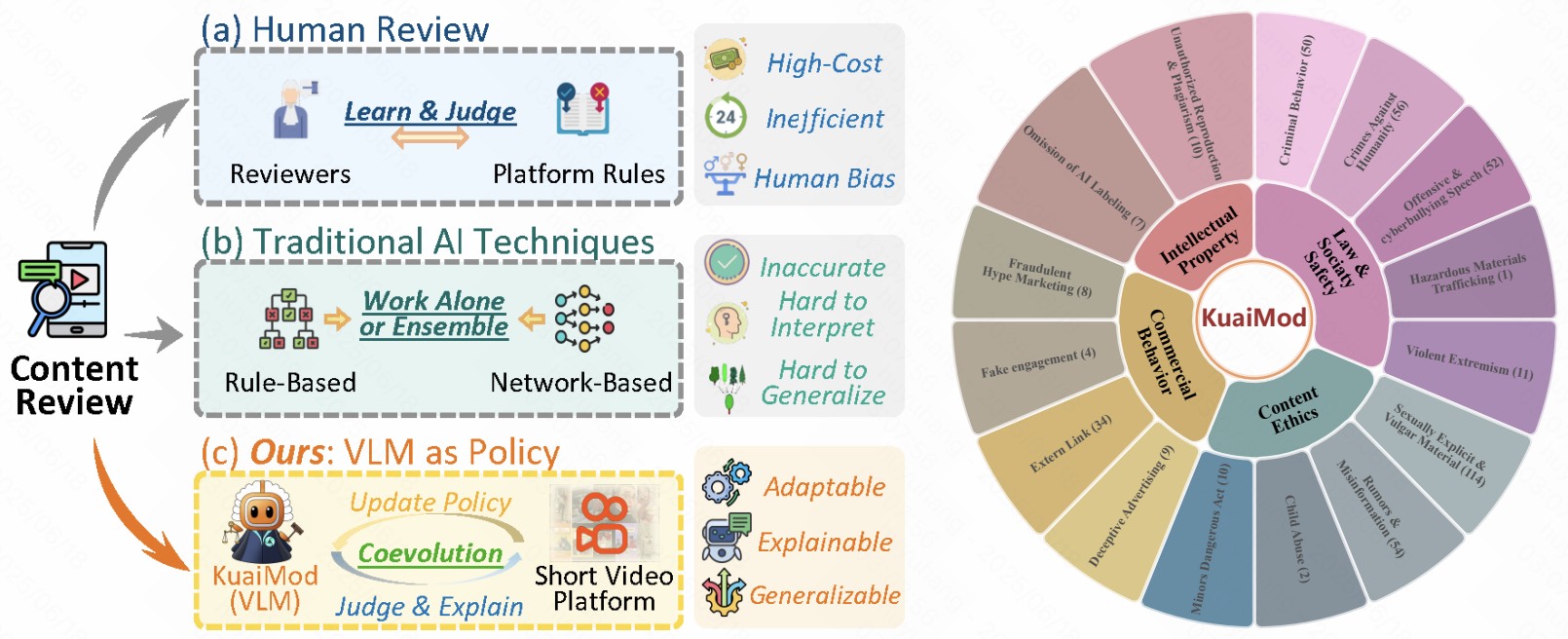
Exponentially growing short video platforms (SVPs) face significant challenges in moderating content detrimental to users' mental health, especially for minors, where dissemination risks catastrophic societal consequences. Existing methods suffer three critical limitations: 1) Manual review incurs high costs and human bias; 2) Automated methods lack nuanced understanding, reducing accuracy; and 3) Industrial regulations adapt slowly to evolving trends due to long update cycles. To address these, we: 1) annotate the first SVP content moderation benchmark with authentic user/reviewer feedback; 2) verify limitations through benchmark evaluation; and 3) propose KuaiMod—a common-law framework with three components: training data construction, offline adaptation, and online deployment & refinement. Leveraging VLM and Chain-of-Thought reasoning, KuaiMod dynamically models video toxicity from sparse feedback, achieving rapid updates and high accuracy. Offline experiments and large-scale A/B tests show KuaiMod achieves best benchmark performance, reduces user reporting by 20%, and increases DAU/AUT on Kuaishou platforms. Benchmark open-sourced at KuaiMod.github.io.
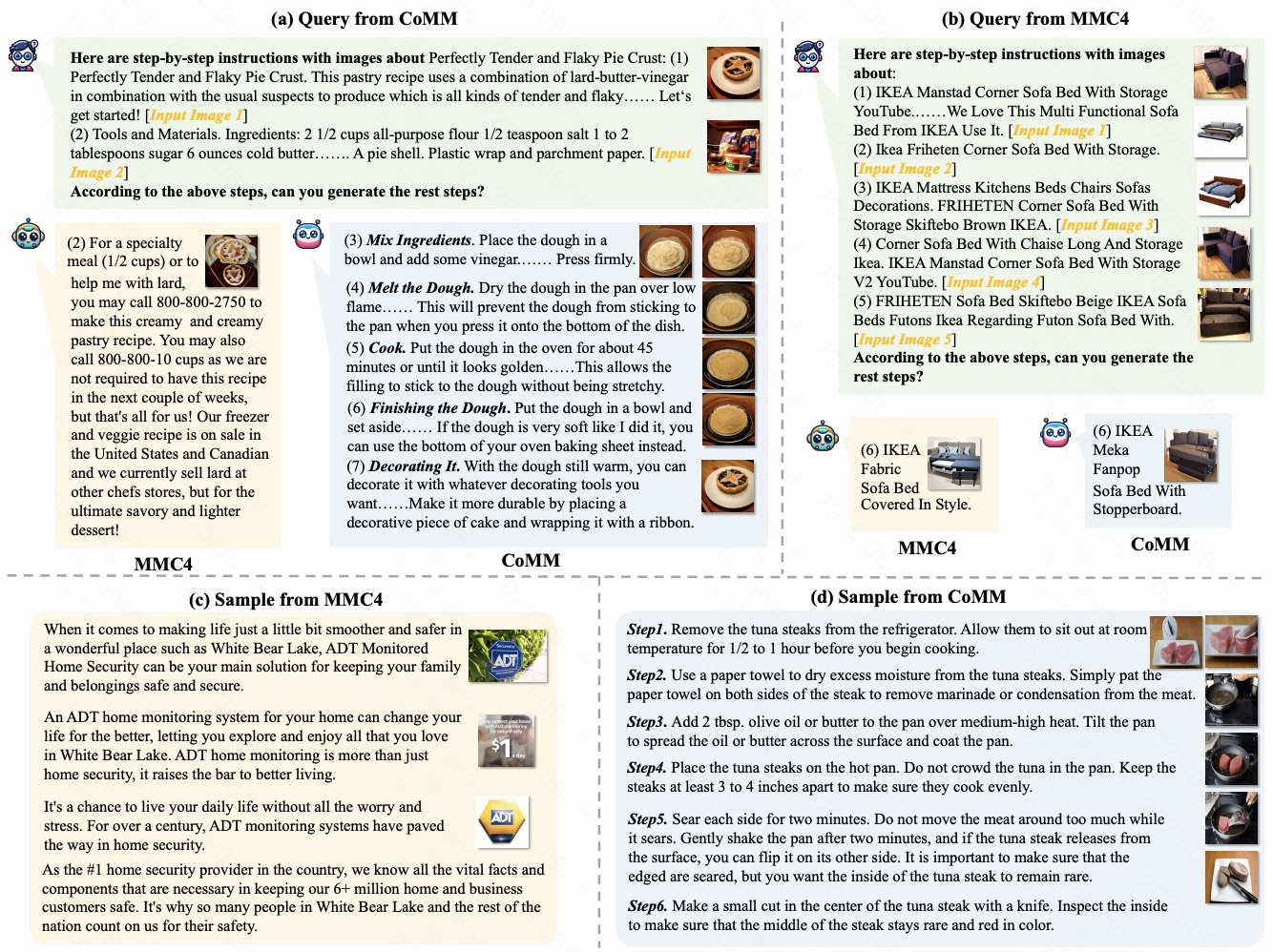
Interleaved image-text generation is a vital multimodal task, but generating sequences with narrative coherence, entity/style consistency, and alignment remains challenging due to poor training data quality. To address this, we introduce CoMM, a high-quality Coherent interleaved image-text MultiModal dataset designed to enhance coherence, consistency, and alignment. CoMM harnesses raw data from diverse sources (instructional content and visual storytelling) as a foundation, then applies a multi-perspective filter strategy using advanced pre-trained models to ensure sentence development, image consistency, and semantic alignment between images and text. Quality evaluation metrics confirm the dataset's high quality, while extensive few-shot experiments demonstrate CoMM's effectiveness in enhancing multimodal large language models' (MLLMs) in-context learning capabilities. We also propose four new tasks and a comprehensive evaluation framework to assess interleaved generation abilities, opening new avenues for advanced MLLMs with superior multimodal understanding.
Large Vision-Language Models (LVLMs) have achieved significant progress, but expensive inference costs limit realistic deployment. While existing works compress visual tokens by identifying important non-redundant tokens as targets (pruning/merging others), they face two dilemmas: 1) the token importance-redundancy dilemma in target token identification, and 2) the conflict between disrupting target token information and losing non-target token information during merging/pruning. To solve these, we propose Libra-Merging—a novel visual token compression scheme. For target token identification, it selects the most important tokens from spatially discrete intervals, achieving more robust importance-redundancy trade-offs than hyper-parameter-dependent methods. During token compression, it avoids merging non-target tokens dissimilar to targets (preventing target information disruption) while condensing them into an information compensation token to retain critical non-target information. Serving as a plug-in for diverse LVLMs, extensive experiments demonstrate its effectiveness, with code available at https://github.com/longrongyang/Libra-Merging.

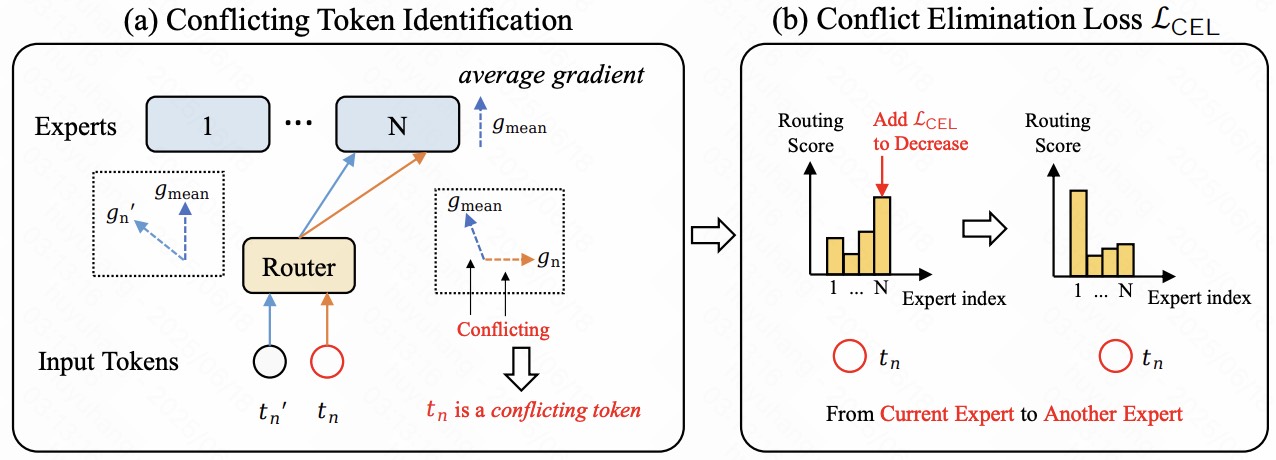
The Mixture-of-Experts (MoE) approach in Large Vision-Language Models (LVLMs) uses sparse models to achieve comparable performance with fewer activated parameters during inference, reducing costs. However, existing MoE methods employ routers that are not optimized for distinct parameter optimization directions from tokens within an expert, causing severe interference between tokens. To address this, we propose Solving Token Gradient Conflict (STGC), which utilizes token-level gradient analysis to identify conflicting tokens in experts and adds a tailored regularization loss to encourage routing conflicting tokens away from their current experts, thereby reducing intra-expert interference. STGC serves as a plug-in for diverse LVLM methods, with extensive experiments demonstrating its effectiveness. The code will be available at https://github.com/longrongyang/STGC.
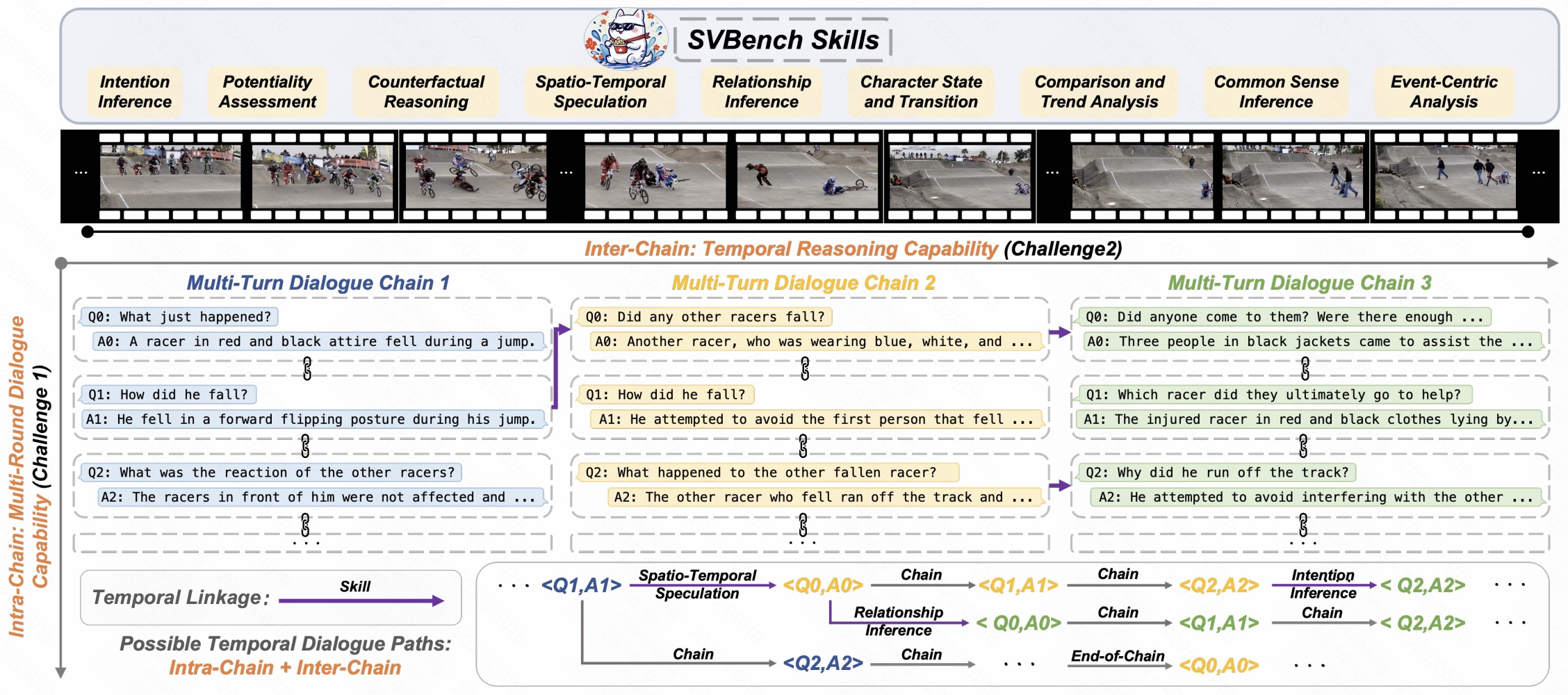
Despite significant advancements of Large Vision-Language Models (LVLMs) on established benchmarks, there remains a gap in evaluating their applicability in long-context streaming video understanding, as current video understanding benchmarks emphasize isolated single-instance text inputs and fail to assess the capacity to sustain temporal reasoning throughout video streams. To address this, we introduce SVBench, a benchmark with temporal multi-turn question-answering chains for thoroughly assessing streaming video understanding capabilities. Using a semi-automated annotation pipeline, we generate 49,979 Question-Answer (QA) pairs from 1,353 streaming videos, including QA chains representing consecutive multi-turn dialogues over video segments and temporal linkages between successive chains. Experimental results from 14 models in dialogue and streaming evaluations reveal that while closed-source GPT-4o outperforms others, most open-source LVLMs struggle. We also construct StreamingChat, which significantly outperforms open-source LVLMs on SVBench while achieving comparable performance on diverse vision-language benchmarks. We expect SVBench to advance streaming video understanding research by providing comprehensive analysis, with our benchmark and model accessible at https://yzy-bupt.github.io/SVBench.
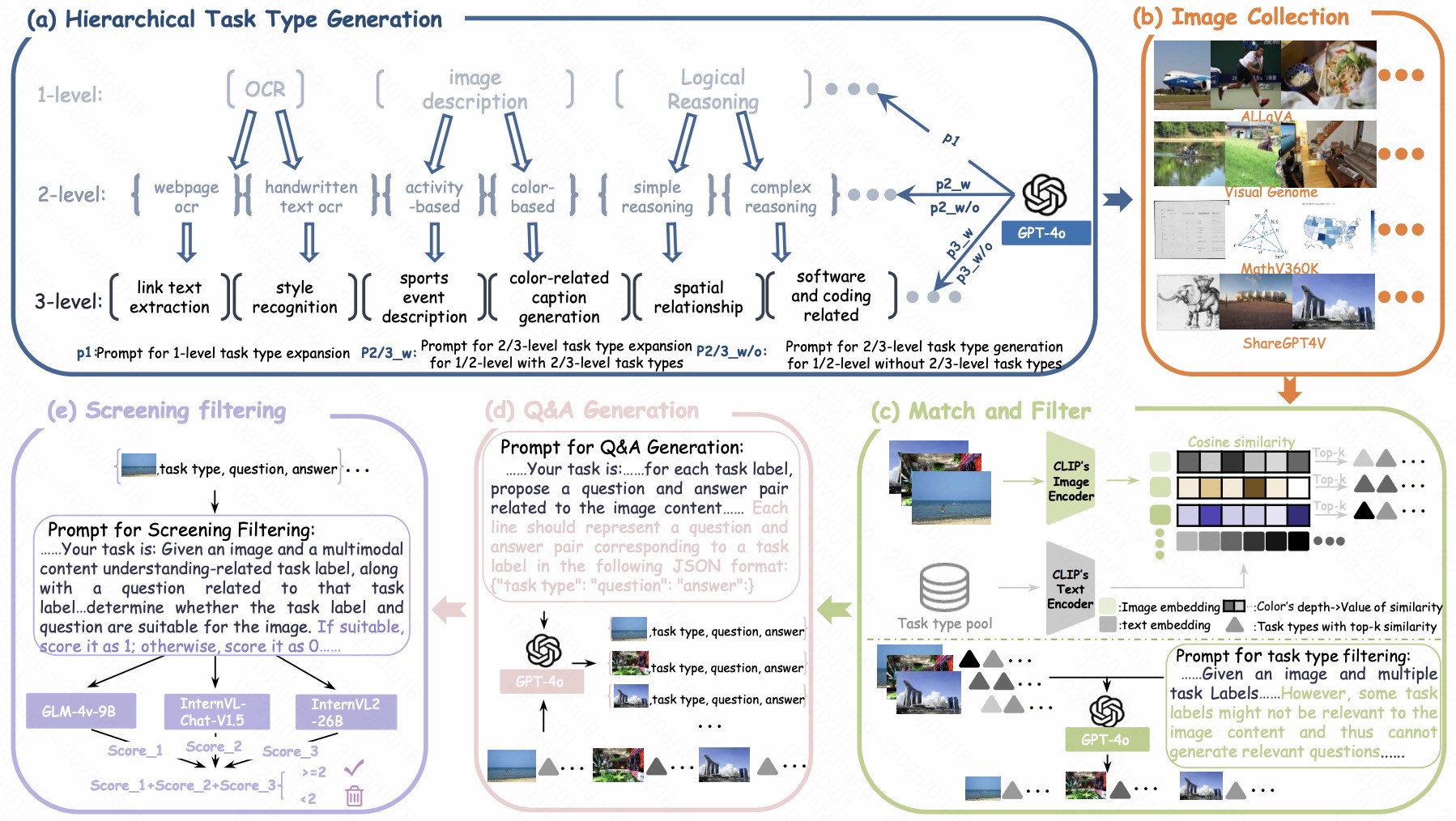
Multimodal visual language models are advancing in open-world applications but face limitations due to insufficient task-specific data, causing poor generalization and biased outputs. While increasing task diversity in fine-tuning datasets is crucial, manual task labeling is labor-intensive and typically yields only a few hundred task types. To overcome this, we propose TaskGalaxy, a large-scale multimodal instruction fine-tuning dataset with 19,227 hierarchical task types and 413,648 samples. TaskGalaxy uses GPT-4o to expand task diversity from a small set of manually defined tasks, employs CLIP and GPT-4o to filter tasks best matching open-source images, generates relevant question-answer pairs, and leverages multiple models to ensure sample quality. This automated approach enhances task diversity and data quality while minimizing manual effort. Integrating TaskGalaxy into models like LLaVA-v1.5 and InternVL-Chat-v1.0 demonstrates substantial performance gains across 16 benchmarks, highlighting the critical role of task diversity. TaskGalaxy is publicly available at https://github.com/Kwai-YuanQi/TaskGalaxy.